Project 1: Predict Call Drop Category.
I finished this project in Apr’20. There is no Github solution that I could find for this project. As such, every step & code was developed based on my own thinking which I believe strongly represents my understanding of applying ML concepts.
Introduction
The data is captured for various service providers, at multiple locations, network types 3G, 4G, 2G, ratings, coorditanes etc. The data attached is for two different months. Predict Call Drop Category using ML algorithms.
Data
- Call Drop Category: Target Variable. (3 different categories)
- Operator: Categorical (10 different categories)
- Status: Categorical (3 categories: Indoor, Outdoor, Travelling)
- Network type: Categorical (4 categories: 2G, 3G, 4G, Unknown)
- Rating: Ordinal (1-5)
- Latitude
- Longitude
- State Name
Evaluation metric
F-1 Score & Confusion Matrix plot: F1 score is the harmonic mean of precision & recall
Logic & sources:
-
F1-score metric is used to find an equal balance between precision and recall, which is extremely useful in most scenarios when we are working with imbalanced datasets (i.e., a dataset with a non-uniform distribution of class labels). here
-
Importance of balance between precision & recall. here
-
Intuition: For other similar self projects, I have used accuracy score, balanced score, roc-auc-score, r2-score (regr.). Through those projects, I have found f1 score to represent model variance explanation the best.
Algorithm attempts
Did dummy variable encoding.
- Null values: Only State names are missing & a huge number. Therefore, dropped State-name variable
Attempt 1:
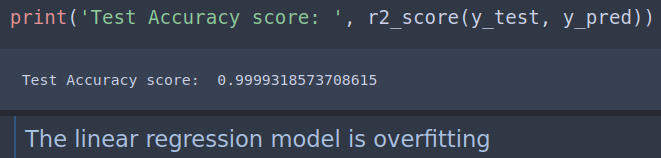
Linear regression & Label encoder. Dropped State-Name, Operator, Network-Type columns.
Attempt 2:
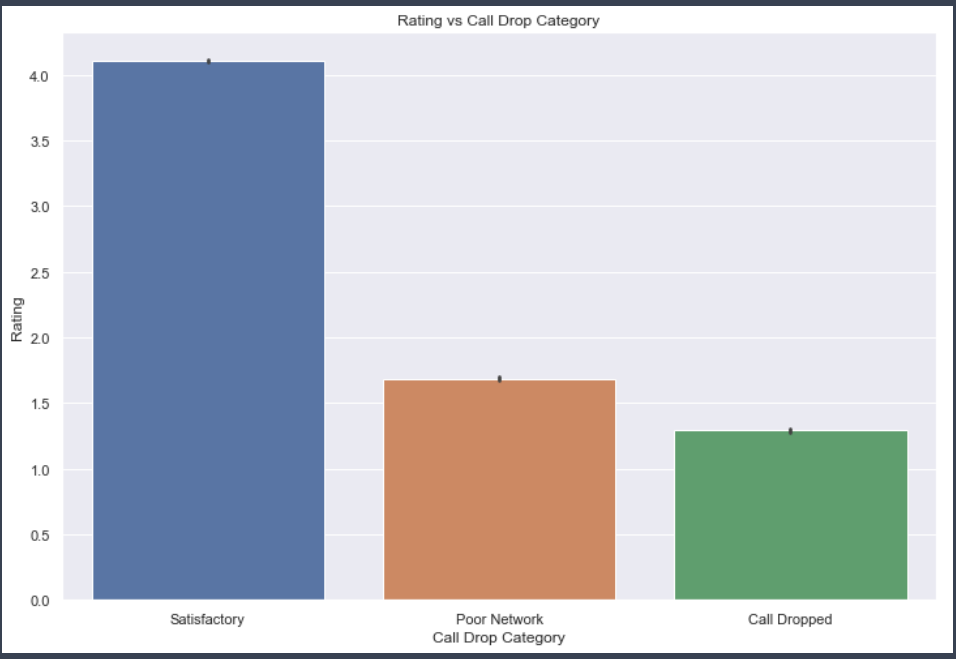
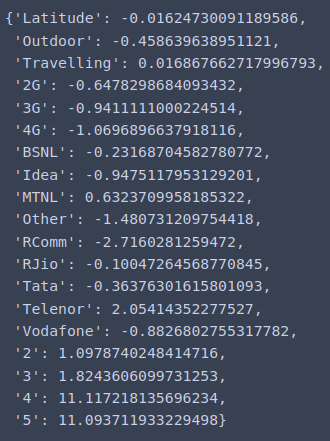
Satisfactory category prediction only attempt.
Applied Logistic Regression, found the coefficients
Metric
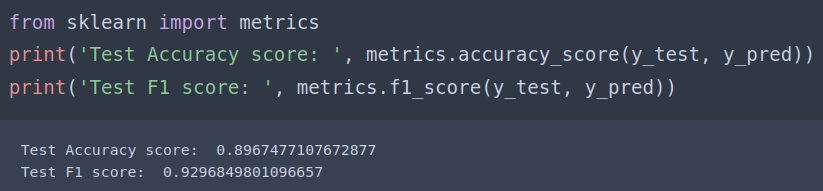
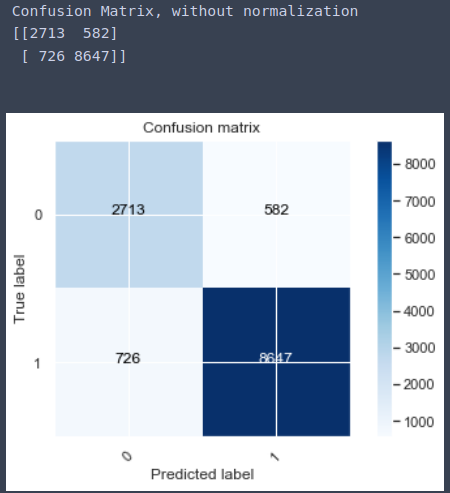
Attempt 3:
Trying to predict all the 3 classes simultaneously.
Two Methods:
Multi-label: If classes are not mutually exclusive.
Multi-class: If classes are mutually exclusive.
In our case, the classes: (Poor network, Satifactory, Call Dropped) are mutually exclusive, therefore I went with multi-class classification. F1 Score was not up to mark. Accuracy Score: 0.75. Went ahead with Attempt 2.
Project 2: ML model deployment.
I finished this project in Mar’20 after finishing my IBM ML specilisation (Kindly see resume).
- Link to the app: App Link;
- If above link not working please copy-paste in your browser: http://insurance-cost-model.herokuapp.com/
- Link to the full repo: github
Introduction
Developing models is excellent, but, I received this particular advice multiple times: “Do not let your model sit on localhost! Deploy it!!” As such, I picked up the Insurance Cost Prediction project & deployed it through Heroku.
Data & Model Development
Data:- 6 input variables (x): Categorical - 3 (gender, smoker, region), Numerical - 3 (Age, BMI, Children) 1 target variable (y): Insurance charges.
Model Development Steps:
- References
- Import Data
- EDA
- Missing Values Imputation (No null values here, but I have tried Mean, Median, Mode imputation in other projects of mine.)
- Data Split into training & testing
- ML model: Lasso Regression (Finalised)
- Accuracy (R2-Score: ~ 0.8 accuracy )
Model Deployment:
- Model pickle -> Flask -> App -> Frontend -> Run & edit on localhost.
- Requirements.txt -> Procfile -> Heroku CLI -> git push heroku master!